

Plus de 4 millions de décisions de justice sont rendues tous les ans en France. Leur diffusion en ligne est essentielle pour les professionnels du droit et les citoyens mais seul 1% est effectivement accessible en version numérique. Alors que le volume de décisions augmente tous les ans, l’anonymisation est au centre des enjeux d’une diffusion plus large de la production jurisprudentielle française.
En accord avec la législation, mais aussi avec son code de bonne conduite, Doctrine a mis en place un algorithme performant et automatique d'anonymisation, grâce à l’intelligence artificielle, afin de publier les décisions de justice dans le respect de la vie privée des personnes concernées.
Dans cet article, nous allons vous expliquer l’évolution des ces méthodes, des outils développés par Doctrine et comment l'apprentissage automatique (machine learning) permet d’automatiser l’anonymisation de gros volumes de décisions avec un taux de succès jusque-là inégalé.
L’anonymisation automatique par règles manuelles et ses limites
Historiquement, l’anonymisation était réalisée manuellement, notamment par les juridictions ou les éditeurs qui ne publiaient alors qu’une infime sélection des décisions. Mais cette anonymisation manuelle, au-delà des problématiques de coût et de transfert des données personnelles associés, comporte un risque élevé d’erreur.
Le développement de l’informatique juridique et notamment la constitution de base de données de décisions de justice mais aussi le déploiement de nouvelles technologies ont entraîné l’essor des méthodes automatiques d’anonymisation.
Le principe général de ces méthodes d’anonymisation automatique est de s’appuyer sur des règles « métier » définies par des membres des juridictions experts sur les questions d’anonymisation. Un exemple simple de règle est par exemple : « Un mot commençant par une majuscule et précédé par « Madame » est un nom de personne physique », afin de repérer les noms et notamment les patronymes.
Ces règles peuvent impliquer des sources externes comme des bases de données de prénoms, de noms ou d’adresses, on parle alors d’approche « thésaurus » ou « dictionnaire ». De plus, plusieurs règles peuvent être imbriquées les unes dans les autres. De telles règles peuvent aussi dépendre des habitudes de rédaction propres à chaque greffier. Ainsi, certains greffiers écrivent Monsieur, d’autres M. et d’autres encore Mr. Les règles doivent donc s’appuyer sur ces tendances rédactionnelles pour être capables de capturer toutes les variations de syntaxe.
Ces règles permettent ensuite de créer des algorithmes, suites d’opérations informatiques, permettant une anonymisation automatique. Lorsque l’algorithme analyse une nouvelle décision, il lit cette dernière, mot par mot, et repère les différents mots à anonymiser.
Après cette première phase d’identification des mots à anonymiser, il est nécessaire de gérer les coréférences (ou plusieurs façons de référencer une même entité dans un texte). Ainsi, l’algorithme doit comprendre que « M. Paul Émile Dupont », « Paul », « Monsieur Dupont » font référence à une seule et même personne et doivent être remplacés par « M. X », afin que la décision reste compréhensible et lisible.
Ces méthodes d’anonymisation automatiques posent principalement trois problèmes :
Exhaustivité des règles
Tout d’abord, aussi complexes ces règles soient-elles, elles ne sauraient être exhaustives. Ainsi, une approche « thésaurus » sur les prénoms et noms de personnes sera peu efficace pour repérer les noms rares. Par ailleurs, la politique d'anonymisation dans le domaine juridique est plus subtile : si les personnes physiques doivent être anonymisées, les mentions aux magistrats et avocats, elles, sont préférentiellement conservées ; cela complexifie d'autant plus les règles. A titre d'exemple, voici quelques cas et les résultats avec une règle simple qui anonymiserait tous les noms en majuscule suivant le terme Monsieur:

Sur ces 5 exemples, seul 1 cas est bien traité par une règle manuelle simple.
Ce cas illustre la complexité des règles à mettre en place, ainsi que la nécessité de prendre en compte le contexte du nom pour distinguer les noms propres à anonymiser, des noms propres à conserver.
Stabilité des règles
Les règles manuelles, soumises à l’épreuve du temps, se révèlent de moins en moins efficaces en l’absence de maintenance. Ainsi, si une règle s’appuyait sur les tendances de rédaction d’un greffier et que ce dernier venait à être remplacé, l’algorithme perdrait alors en précision. Or, ces méthodes ne permettent pas de corriger l’algorithme automatiquement et il faudra réécrire de nouvelles règles spécifiques à la lumière des changements rencontrés. Cette maintenance n’est pas sans risque puisque la création de chaque nouvelle règle peut venir « casser » les règles précédentes.

Exploitation des résultats
L'algorithme, aussi performant soit-il, peut présenter des erreurs. Il peut alors être pertinent de mettre en place un système de vérification manuelle sur les anonymisations sur lesquelles nous avons des doutes. Or, par définition d'une règle manuelle, celle-ci est vérifiée ou non, et ne fournit pas d'information sur la fiabilité de la prédiction. Il pourrait par exemple être pertinent de mettre en place un système de vérification manuelle sur des exemples comme Monsieur le Préfet, qui d'un point de vue syntaxique ressemblent fortement à un nom propre (par exemple, proche de Monsieur le Guellec). Des méthodes plus poussées utilisant du machine learning fournissent non seulement une prédiction, mais également une probabilité (seuil de confiance) sur la prédiction, qui peut être exploitée ensuite pour de la vérification manuelle, ou pour analyser les exemples sur lesquels le modèle est moins certain.
La nouvelle méthode : le machine learning au service de l'anonymisation
Nous venons de voir que l'anonymisation manuelle, tout comme sa version automatique par règles, ne permet pas d'anonymiser un nombre important de décisions avec un taux de réussite acceptable.
Ce constat est exactement celui que nous avons fait chez Doctrine lors des premières phases de développement du produit en 2016, nous amenant à nous tourner vers des méthodes nouvelles basées sur l'apprentissage machine ou apprentissage automatique (aussi appelé "machine learning" en anglais) pour pallier les limites précédemment décrites dans le cas de l'anonymisation.
Apprentissage automatique et anonymisation
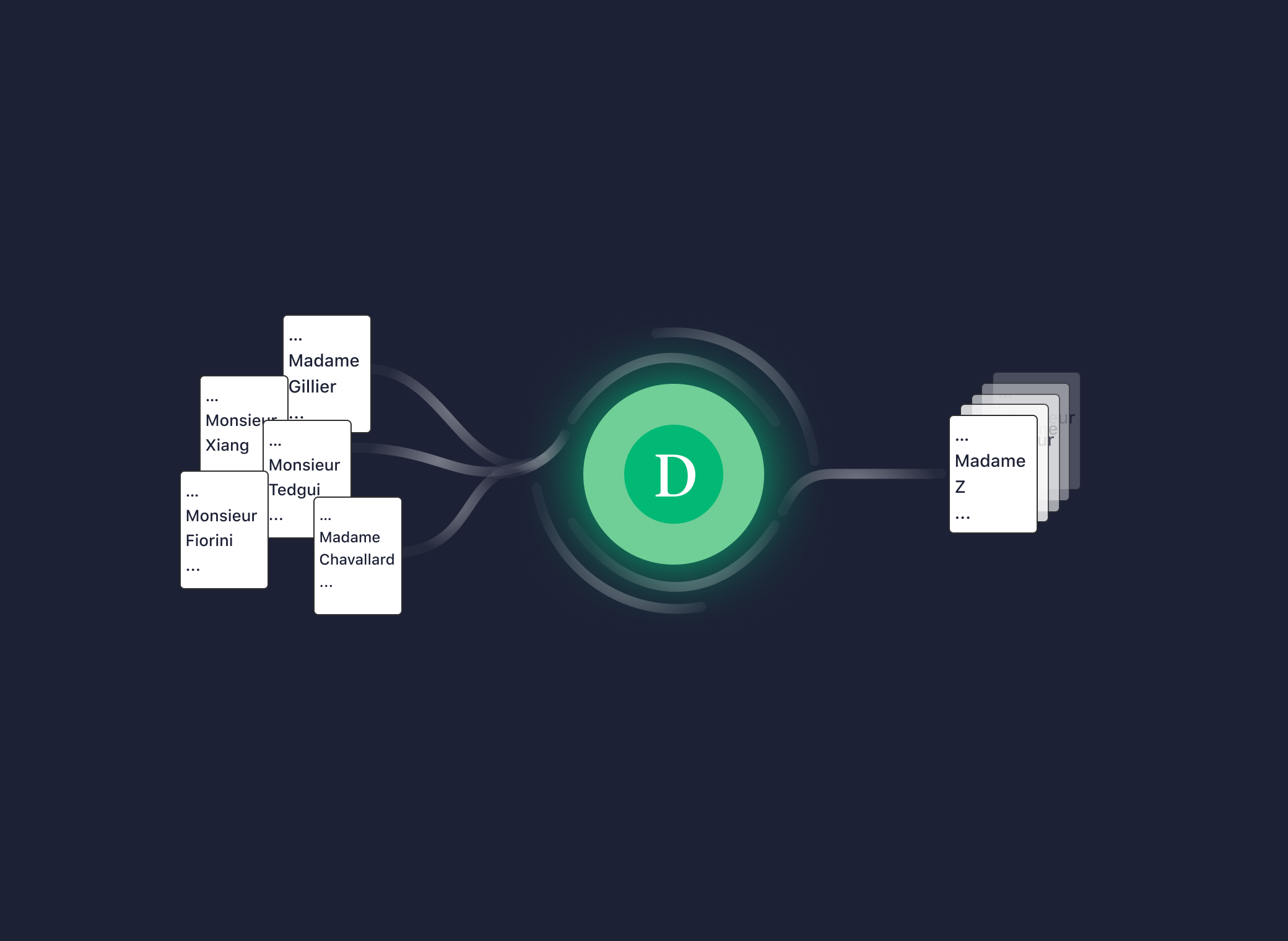
L'apprentissage automatique consiste à laisser une machine, en l'espèce un ordinateur, apprendre à résoudre une tâche avec peu d'intervention humaine. Concrètement dans notre cas, il s'agit en fait de développer un algorithme dont le but sera d'anonymiser automatiquement des décisions de justice. Cet algorithme se présente sous la forme d'un modèle mathématique appelé "réseau de neurones" et qui possède des millions de paramètres. Tout l'enjeu va être de lui apprendre à ajuster ces paramètres, au départ aléatoires, pour reconnaître les passages à anonymiser étant donné une décision de justice en entrée.
Pour ce faire, il faut lui apprendre à distinguer ce qu'est un passage à anonymiser de ce qui n'est pas un passage à anonymiser en lui montrant des dizaines de milliers voire des centaines de milliers d'exemples. Ces exemples constituent ce qu'on appelle un jeu de données d'entraînement annoté, où on retrouve la version originale et la version anonymisée (obtenue via les méthodes manuelles et par règles évoquées précédemment) d'un ensemble de décisions. La constitution de ce dernier est d'ailleurs cruciale pour avoir un algorithme performant, nous y reviendrons dans la suite.
Le processus d'apprentissage du modèle aussi appelé entraînement du modèle se déroule alors ainsi :
- On donne une décision de justice à anonymiser au modèle, étant donné les paramètres du modèle, il va alors sortir une liste des passages à anonymiser.
- On lui montre ensuite les passages qu'il fallait anonymiser.
- Le modèle compare ce qu'il a anonymisé avec les passages à anonymiser et apprend de ses erreurs en mettant à jour ses paramètres intrinsèques pour que les passages correspondent à ce qu'il fallait anonymiser.
- On répète ce processus sur l'ensemble des exemples jusqu'à ce qu'on atteigne un taux de réussite suffisant.
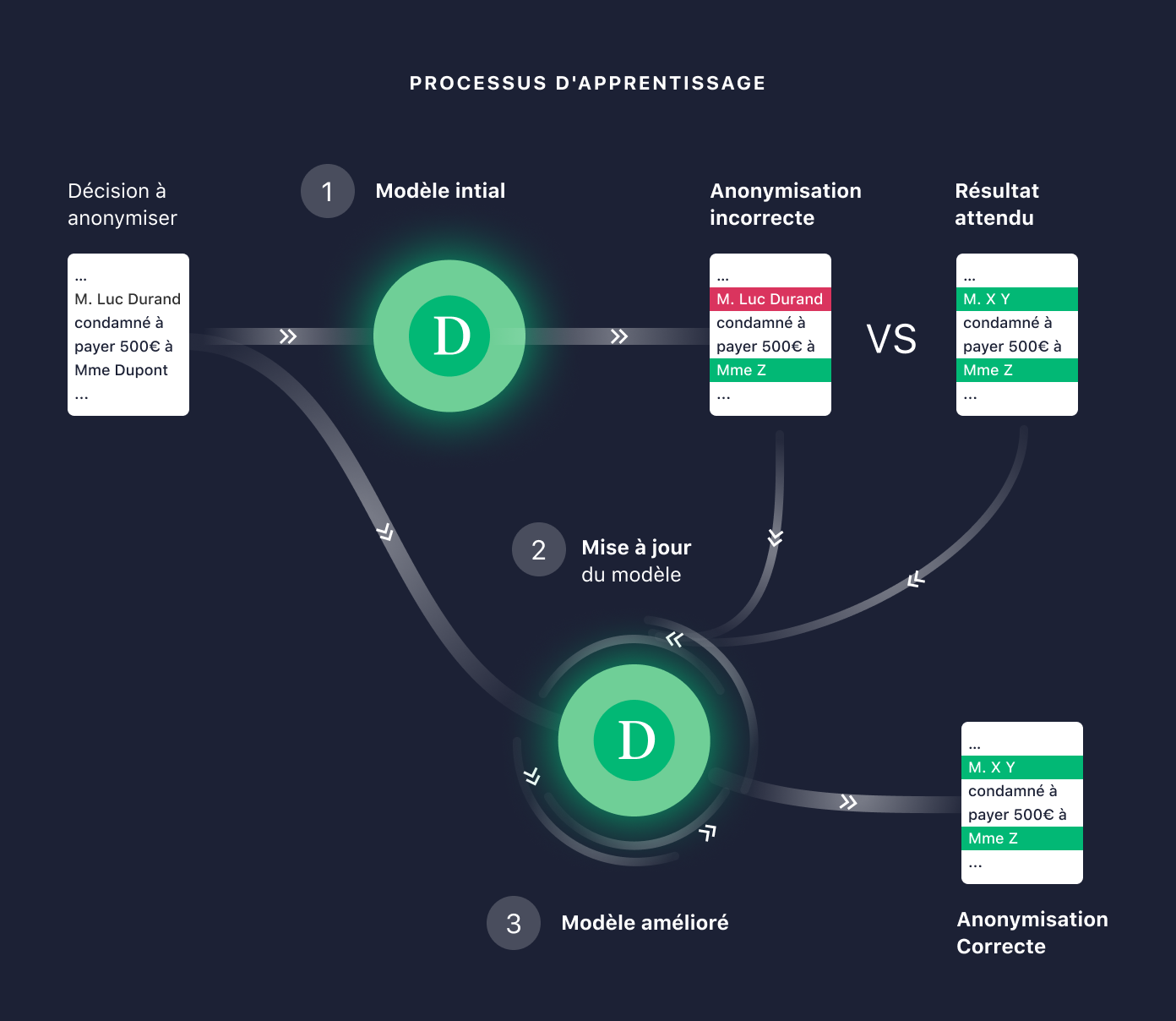
Le taux de réussite est mesuré sur une partie isolée du jeu de données initial qu'on ne montre pas au modèle lors de son apprentissage. Cela permet de ne pas biaiser les résultats, car intuitivement, il lui aurait été très simple d'anonymiser une décision pour laquelle il a déjà vu la version anonymisée.
Ainsi, via ce processus, le modèle apprend par lui-même les règles qui lui permettent de déterminer si un passage est à anonymiser ou non.
La reconnaissance d'entités nommées
L'algorithme utilisé pour le cas d'usage de l'anonymisation s'appelle la reconnaissance d'entités nommées. Il repose sur 3 grands principes du traitement du langage naturel :
- Modélisation de l'aspect sémantique des mots
Le modèle comme tout programme informatique ne comprend pas les mots tels que nous les comprenons. Il voit les mots comme une séquence de nombres de telle sorte que les mots similaires ont une représentation sous forme de nombres similaires. Ce qui fait que le modèle va comprendre qu'il ne faut pas anonymiser l'expression "Monsieur Martin, Juge" s'il a déjà vu l'expression "Madame Dupont, Magistrate" auparavant car "juge" et "magistrate" auront des représentations très similaires.
- Prise en compte du contexte du mot
Une force principale de ce modèle réside dans le fait que ces règles peuvent tenir compte du contexte pour anonymiser. Par exemple, il saura qu'il ne faut pas anonymiser "Monsieur Durand" dans "Monsieur Durand, président à la Cour" car il aura associé "président à la Cour" à "Monsieur Durand".
Un autre exemple est que dans le cas d'une personne physique "Madame Pauline Chavallard", le modèle saura que le mot après "Pauline" a de grandes chances d'être un nom car il aura vu dans les exemples le motif récurrent prénom suivi du nom.
- Exploitation des caractères qui composent le mot
Enfin, au-delà du mot et de son contexte, et via les exemples qu'il aura vus, le modèle comprendra intrinsèquement comment déceler un nom ("Dupont") d'autres entités comme une plaque d'immatriculation ("AA-123-BB") ou d'un numéro de téléphone ("0601010101") car ils ne sont pas composés des mêmes types de caractères.
Une fois l'entraînement défini précédemment terminé, le modèle est prêt à être utilisé en conditions réelles sur les décisions à anonymiser. Pour donner un ordre de grandeur sur la performance, un tel modèle est capable de bien identifier les mots à anonymiser dans 98% des cas.
Nos initiatives pour aller plus loin
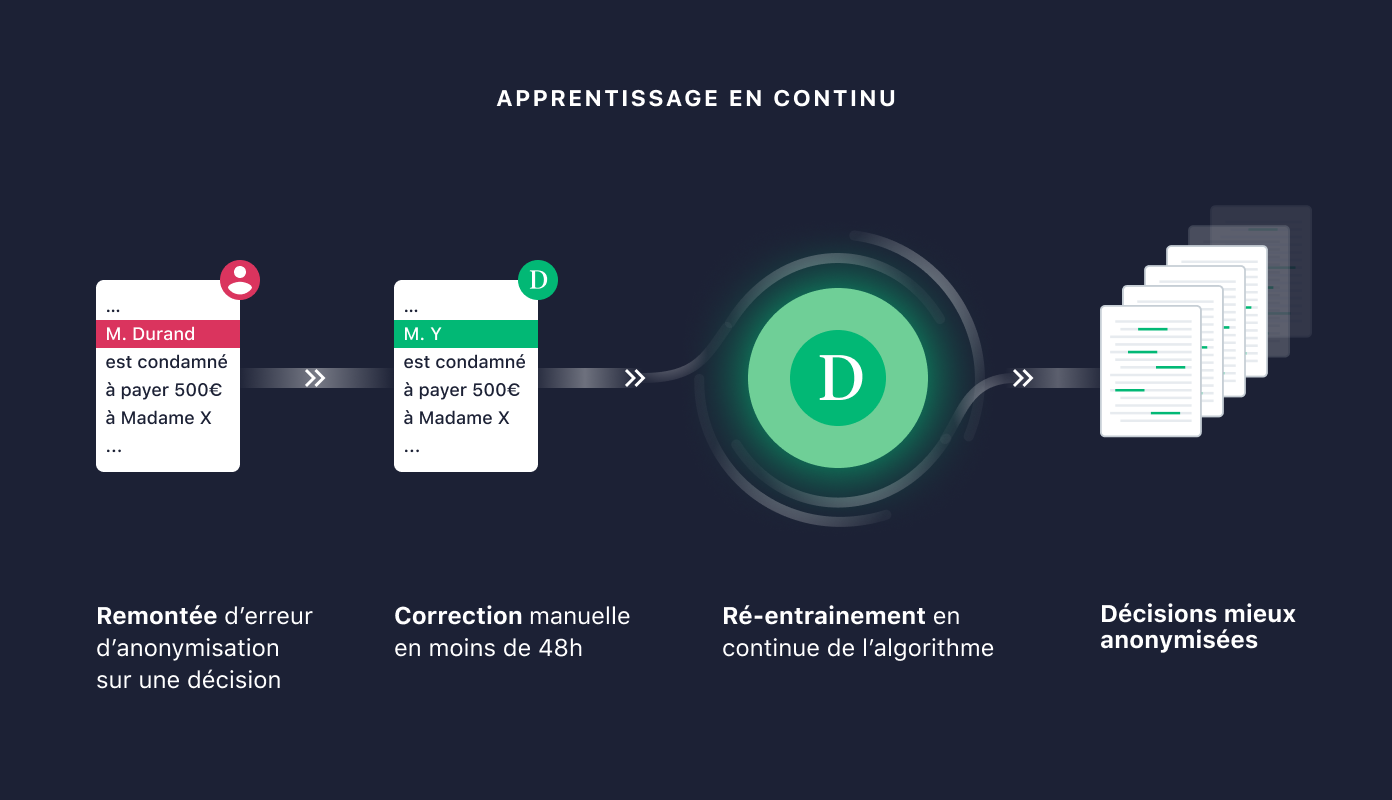
Apprentissage en continu
Ce type de modèle, certes performant, n'a pas un taux de réussite parfait. En effet, les motifs plus atypiques, qu'il n'a pas observés dans le jeu de données d'entraînement, ne sont pas toujours bien détectés. C'est ce qu'on appelle un biais.
Ce peut être le cas des noms très rares et dont la syntaxe est plus originale (exemple: Kerbourc'H), ou bien les cas où seul un prénom est mentionné (c'est souvent le cas lorsqu'on désigne des enfants dans une décision), car le modèle est habitué à voir une combinaison du prénom avec un nom.
Comme le modèle fait des erreurs, Doctrine s'engage à rectifier ces erreurs en moins de 48 heures. Nous collectons ainsi depuis plusieurs années des données sur lesquelles le modèle est moins performant. Cette collecte permet ainsi de générer des nouvelles données annotées à montrer au modèle, lui permettant ainsi de s'améliorer via un ré-entraînement, comme décrit à la section précédente.
Au-delà de la simple rectification des erreurs relevées, l'objectif est donc de permettre à notre modèle de s'améliorer en continu pour offrir une pertinence sans cesse plus élevée.
Veille scientifique
La recherche académique est par ailleurs toujours très active sur le traitement du langage naturel, des avancées récentes majeures ont notamment permis des gains de performances significatifs sur ce type de tâches.
Par exemple, les algorithmes utilisés jusqu'à aujourd'hui ne géraient pas, ou mal, les longs documents. De nouvelles méthodes publiées très récemment permettent une gestion plus efficace de ce type de documents, et pourraient alors bénéficier à la compréhension des décisions de justice qui sont par nature très longues.
Doctrine s'engage à suivre ces avancées et à saisir les opportunités associées pour améliorer toujours plus le système d'anonymisation.
Conclusion
La diffusion en ligne des décisions de justice, telle qu’elle est prévue par la loi, requiert des mesures adaptées de protection de la vie privée des justiciables.
Seule une anonymisation par des techniques de machine learning permet d'anonymiser un nombre important de décisions avec un taux de réussite très élevé, et répondre ainsi aux enjeux liés à la protection des données personnelles.
L’apport de l’intelligence artificielle est déterminant pour permettre un accès plus large au droit.
Pour faire de l’open data des décisions de justice une réalité, Doctrine a, depuis ses débuts, innové et mis en place des algorithmes correspondant au plus haut état de l'art pour répondre à cette problématique.
