

Introduction
Chercher une aiguille dans une botte de foin. Voilà ce qu’est le quotidien des professionnels du droit. Trouver l’information qui fera la différence dans le conseil apporté par l’avocat à ses clients ou le juriste à son entreprise.
Avec 4 millions de décisions de justice rendues tous les ans et plus de 300.000 articles législatifs et réglementaires en vigueur depuis 2019 seulement, sans compter les centaines de milliers de commentaires doctrinaux, naviguer dans l’information juridique peut relever du challenge pour les professionnels du droit. Le défi n’est pas simplement de permettre une seule et unique recherche au sein de toute l’information juridique disponible, mais bien d’identifier l’information clé.
L’intelligence artificielle a fait naitre une nouvelle génération de moteurs de recherche qui ne se contente plus de ressortir une liste à rallonge de documents associés à des mots clés mais en plus isole les informations qui auront du sens dans le contexte du dossier travaillé.
Mais pour qu’un moteur de recherche soit performant, un pré-requis essentiel est que la technologie comprenne le langage juridique pour comprendre le sens de la question posée par le professionnel du droit. L’enjeu est de taille puisque ces contenus juridiques se composent principalement de textes (décisions de justice, contenus législatifs et doctrinaux) qui sont rédigés de manière très variable et non uniformisée.
Dans cet article, nous levons le voile sur 4 ans de recherche et développement sur le fonctionnement de la compréhension automatique du langage juridique grâce à l’intelligence artificielle dans la technologie Doctrine.
Les enjeux liés à la compréhension du langage juridique
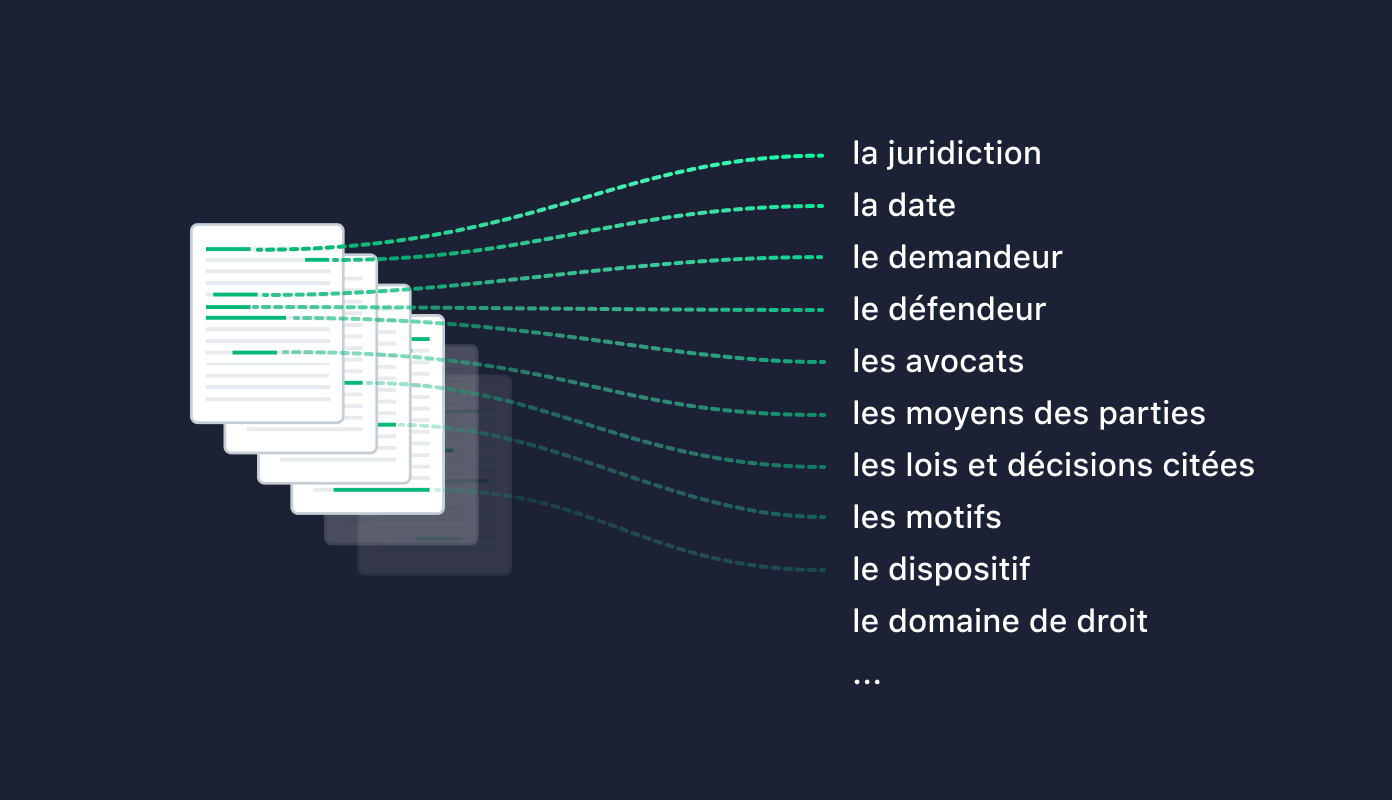
Pour les ingénieurs de Doctrine, il convient de comprendre les documents juridiques et d'étudier leur sens et leurs dynamiques. Par exemple, une décision de justice met en jeu un demandeur, un défendeur, des avocats qui présentent des moyens aux juges qui rendent leur verdict en les justifiant par des motifs. Une décision peut également faire référence à d'autres entités juridiques comme des lois ou des décisions. Ce sont autant d'éléments à comprendre et à identifier à la lecture du texte.
Cependant, en France, le contenu juridique ne suit pas toujours un format de rédaction homogène et normé.
Les décisions de justice en sont un bel exemple : les différents tribunaux de première instance ont chacun leurs lignes directrices, la rédaction des contenus de l'ordre administratif est par exemple bien plus normalisée que celle de l'ordre judiciaire. Le mode de rédaction peut également évoluer dans le temps. Par exemple, la Cour de cassation a récemment adopté de nouvelles normes de rédaction dans toutes ses décisions.
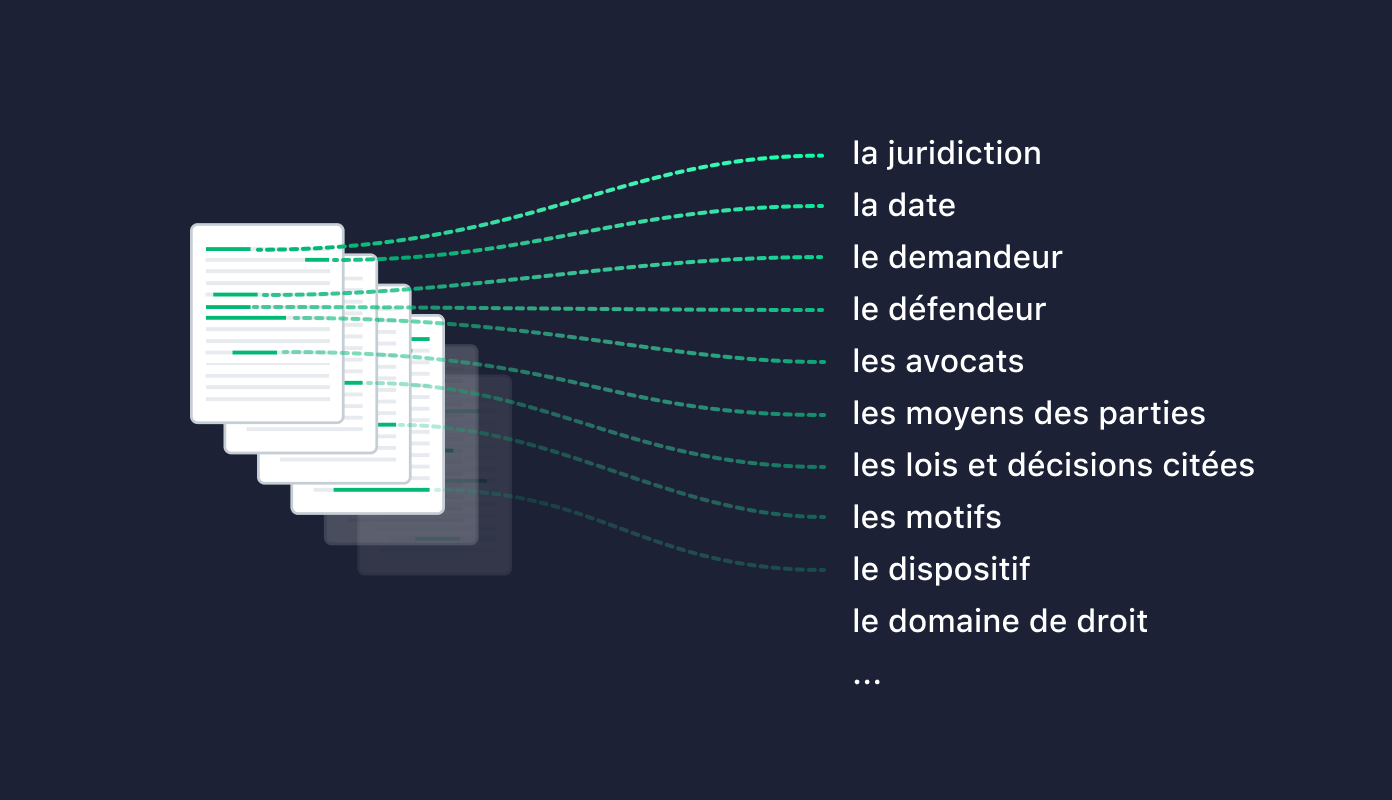
Encore plus complexe, les requêtes écrites en langage naturel par nos utilisateurs dans le moteur de recherche vont souvent contenir un vocabulaire différent. Ainsi, un utilisateur va taper remboursement pass navigo pour adresser la problématique du remboursement des frais de transport mentionnée dans les lois et les décisions.
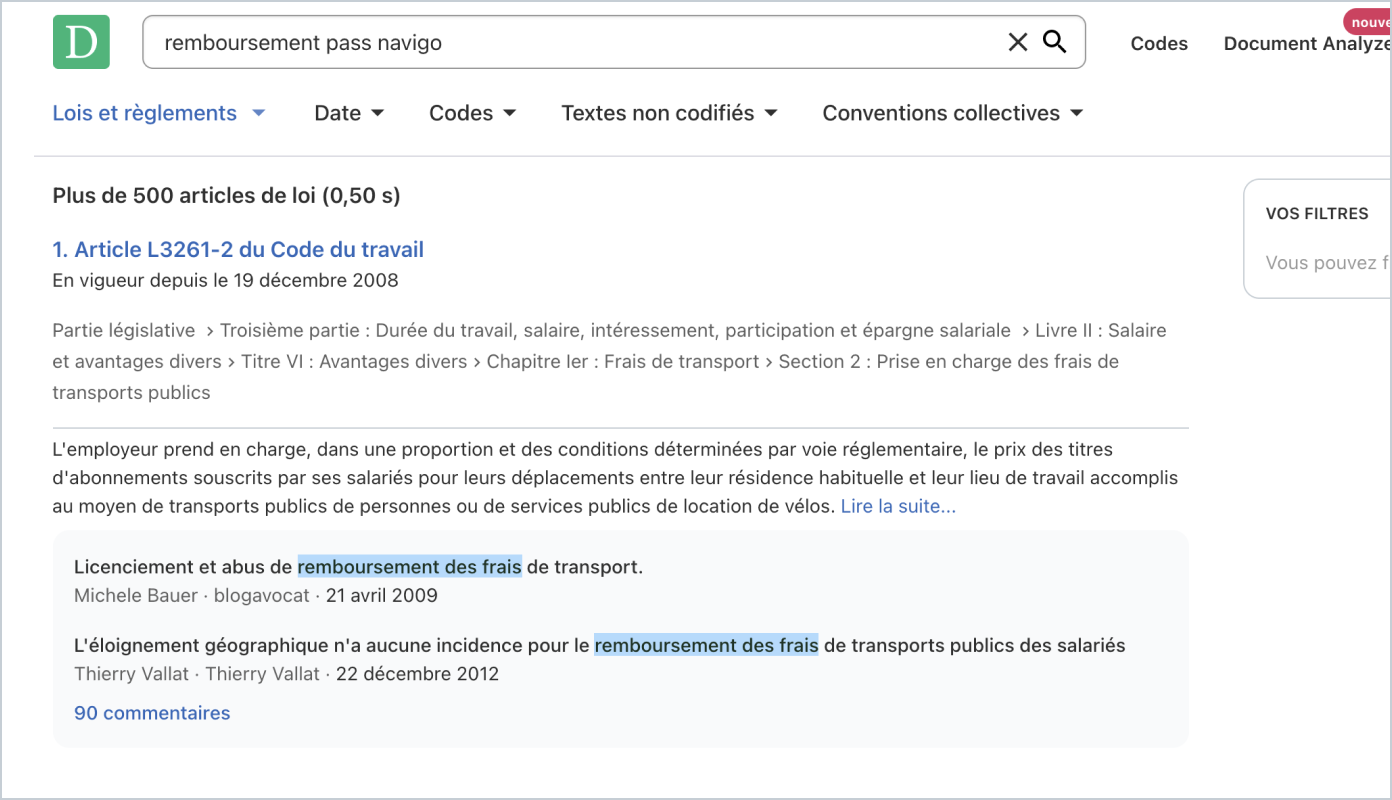
De la même manière, les mentions à la loi sont rédigées de manière différente selon les contenus :
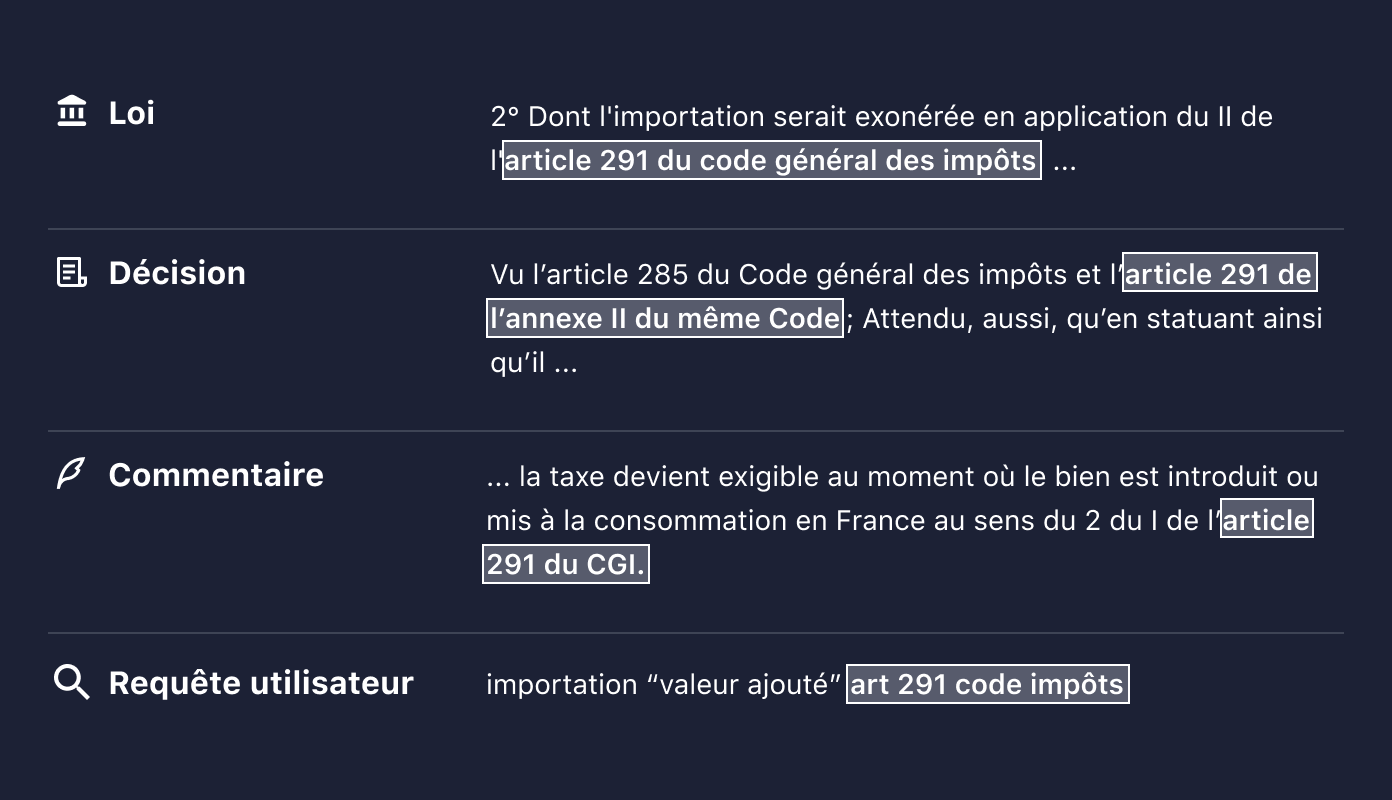
Enfin, un même mot peut faire référence à des entités différentes, en fonction du contexte. Même pour un humain, il n'est pas toujours aisé de comprendre le langage juridique. Cela demande des compétences et une expertise particulière :

De récentes méthodes d'intelligence artificielle permettent d'adresser ces défis. C'est pourquoi Doctrine a investi dès 2016 sur la compréhension automatique du langage juridique. En particulier, ces méthodes permettent de :
- comprendre des mots dans un certain contexte,
- comparer des mots et détecter des synonymes,
- comprendre des textes, et plus particulièrement des textes juridiques.
Comment l'intelligence artificielle permet de comprendre le langage juridique
Comprendre un domaine spécifique : le langage juridique
Comprendre le langage juridique est un enjeu particulier : même pour un humain, ce n'est pas une tâche facile ! Les concepts sont subtils, diversifiés et très spécifiques.
La compréhension du langage juridique s'articule généralement en 3 étapes :
- Apprendre à parler la langue française
Tout comme un être humain, il convient d'abord de savoir parler le français pour ensuite apprendre le droit. Pour cette étape, nous pouvons bénéficier d'algorithmes mis à disposition par des chercheurs du monde entier, en particulier par des entreprises qui bénéficient d'une puissance de calculs bien supérieure aux nôtres. Ces algorithmes ont appris la langue française en lisant plusieurs dizaines de millions de pages du web (comme Wikipedia). Ces algorithmes sont donc très généralistes, et comprennent très bien le français, mais ne maitrisent pas particulièrement le droit.
2. Apprendre le langage juridique
Une fois le français assimilé, on peut apprendre à l'algorithme plus particulièrement le langage juridique généraliste, en lui faisant lire des documents juridiques tels que des décisions, des lois ou des commentaires. A la suite de cette spécialisation, l'algorithme aura une compréhension du mot "avocat" plus proche de l'avocat de la défense que du fruit.
Pour cela, il est nécessaire d'avoir de la donnée juridique (décisions, lois, travaux préparatoires...) en grande volumétrie, ce dont Doctrine bénéficie. Néanmoins, l'algorithme sachant déjà parler le français, une quantité moindre de documents est nécessaire pour avoir des performances acceptables. Chez Doctrine, environ 2 millions de documents juridiques ont été utilisés pour cette étape.

3. Spécialiser l'algorithme sur une tâche précise
Enfin, de la même manière qu'un étudiant en droit peut se spécialiser sur un domaine de droit précis, il faut en général aider l'algorithme à se spécialiser sur des tâches précises (détection des lois, des parties, des avocats, des domaines du droit, ...).
Cette tâche nécessite en général des données annotées, souvent plusieurs milliers d'annotations, pour avoir des résultats acceptables. Néanmoins, plus l'algorithme aura une connaissance profonde du juridique grâce à l'étape précédente, moins il aura a priori besoin de données annotées sur cette spécialisation.
Un exemple d'algorithme qui se base sur cette compréhension automatique du langage, pour ensuite se spécialiser sur une tâche plus précise est l'anonymisation des décisions de justice, pour plus de détails nous avons posté un article spécifiquement sur ce sujet : https://blog.doctrine.fr/lanonymisation-des-decisions-de-justice/.
Ces différentes étapes s'articulent toutes autour de deux enjeux pour l'algorithme :
- Comprendre un mot, dans un contexte donné,
- De manière plus large, comprendre un texte.
Comprendre un mot
Dans le cadre de la compréhension automatique du langage juridique, une méthode nous permettant de faire émerger des synonymes serait un outil extrêmement pratique, car comprendre les variations sémantiques subtiles des mots nous offrirait une plus grande flexibilité lors de l'analyse de ces textes parfois complexes.
Si la compréhension du langage passe avant tout par la compréhension des mots et de leurs significations chez l'humain, on peut légitimement se demander de quoi il retourne pour un système numérique automatisé, notamment lorsqu'il s'agit de savoir quels mots ont un "sens proche".
Notre première intuition, face à cette question, est que fournir au système une liste de synonymes créée par un spécialiste du droit (et qui embarquerait donc la connaissance métier spécifique à ce domaine) permettrait d'amorcer la machine et l'aiderait donc à "comprendre" plus aisément les textes juridiques, qui utilisent un vocabulaire précis et spécifique. Cette approche, bien que probablement efficace sur le court terme, présente deux inconvénients majeurs : elle serait extrêmement coûteuse en temps si l'on voulait avoir les synonymes de tous les mots, et elle deviendrait vite limitée, car elle nécessiterait des mises à jour à chaque introduction d'une nouvelle notion juridique ou de nouveaux mots de vocabulaire.
L'idéal pour notre problème serait d'avoir un algorithme qui quantifie si des mots, ou groupe de mots, sont plus ou moins proches, donc de définir une distance entre les mots. On pourrait alors considérer que les mots ayant une distance très faible sont des synonymes.
Cette distance nous apporterait bien plus d'information qu'une simple liste de synonymes.
Comment un humain a-t-il appris par exemple que les mots "avocat" et "juge" sont similaires, qu'ils définissent tous les deux une personne travaillant dans le milieu de la justice, alors que le mot "pomme" par exemple est très différent ? C'est tout simplement avec des exemples, des cas concrets où ces mots ont été cités dans le même contexte, que l'enfant apprend le sens des mots.
On peut donc dire que deux mots sont proches si l'on peut les retrouver dans le même contexte, c'est-à-dire s'ils sont souvent entourés du même champ lexical. Dans les extraits de phrases suivantes par exemple si les mots "préjudice", ou "dommage" remplaçaient l'espace vide [xxx],les phrases auraient du sens.
les indemnités versées en réparation d’un [xxx] corporel ou moral
au titre de l’indemnisation du [xxx] corporel qu’il avait subi,
On dit donc que ces mots ont été cités dans les mêmes contextes.
Plus les mots vont avoir des contextes en commun, plus on va considérer qu'ils sont proches. Les exemples simples de phrases ci-dessous peuvent nous faire comprendre cela.
Je bois du [ café | thé | jus | vin ]
Le matin je prends du [ café | thé | jus ] au petit déjeuner
J'ai besoin d'une tasse de [ café | thé ] bien chaud pour me réveiller.
Les mots "café", "thé", "jus" et "vin" ont une fonction identique : ils définissent tous une boisson. Ils vont donc se retrouver dans un contexte similaire comme la phrase "Je bois du ...". Néanmoins on va trouver plus de phrases dans lesquelles seuls les mots "café" et "thé" ont un sens, c'est pourquoi l'algorithme va considérer ces mots comme plus proches que les mots "café" et "jus" par exemple. Finalement "café" sera très proche de "thé", un peu moins proche de "jus" et complètement éloigné du mot "arbre" avec lequel il n'a pas de contexte en commun.
Cette méthode de représentation de mots parcourt de nombreux textes et tente de représenter les mots par une suite de chiffres, qu'on appelle un vecteur mathématique. L'ordinateur, qui ne sait traiter que des chiffres, est ensuite capable de calculer très rapidement des distances entre ces représentations des mots qu'il a apprises [1].
Par ailleurs, les représentations ainsi obtenues permettent de donner un sens aux distances entre les mots, au delà de la simple valeur de la distance.
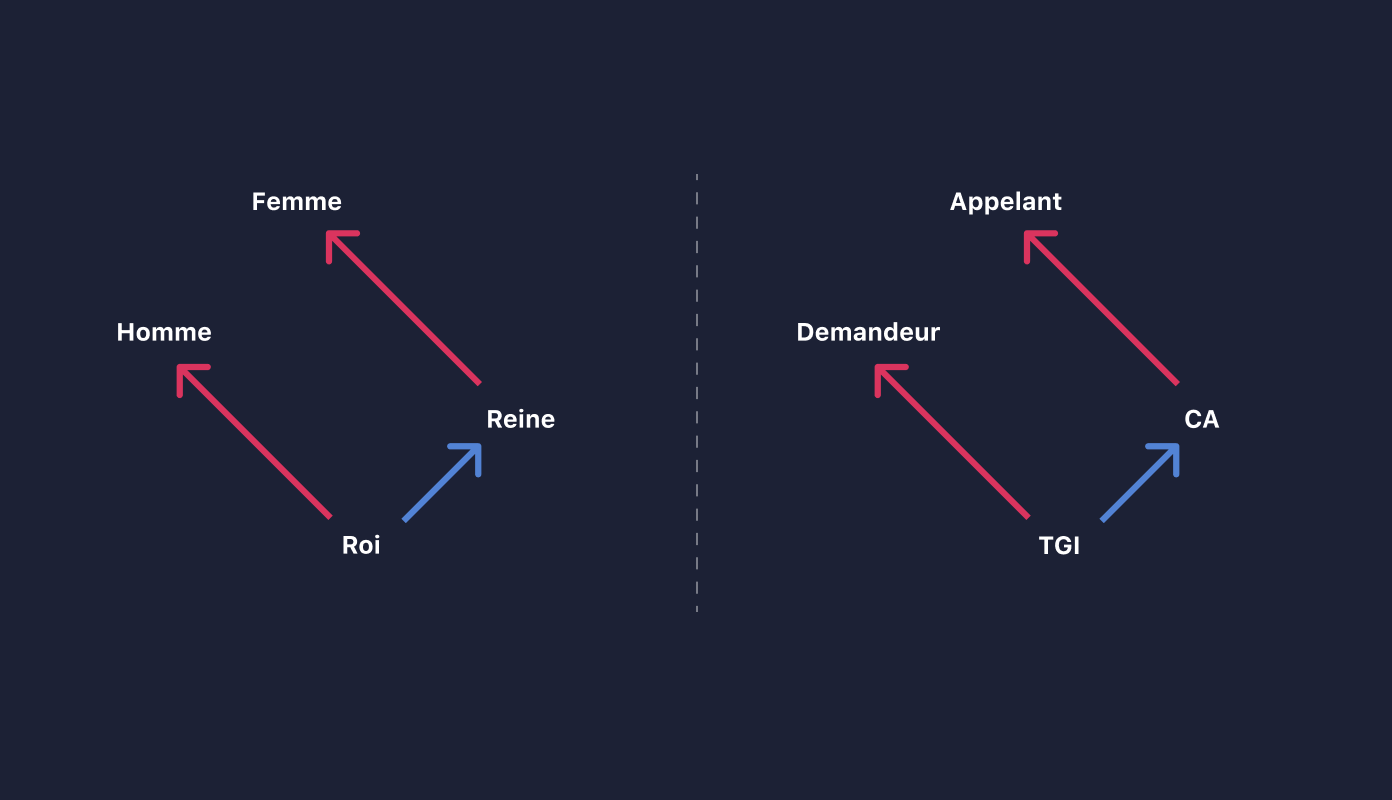
Ainsi les vecteurs représentants les distances entre les mots "homme" et "femme", ou "roi" et "reine" sont les mêmes, car la relation qu'ils modélisent est identique : le fait de passer les mots au féminin.
De la même manière, les distances entre les mots "demandeur" et "appelant" ou "TGI" et "CA" sont identiques car elles modélisent le fait d'interjeter appel.
Ainsi, en plus de trouver des synonymes, l'algorithme est également capable de donner une signification aux relations entre les mots.
Des mots aux textes
Notre algorithme sait donc représenter les caractéristiques sémantiques d'un mot. Mais la plupart des documents juridiques écrits en langage naturel sont des textes entiers, par exemple des décisions de justice ou des lois. C'est donc un ensemble de mots, parfois plusieurs milliers de mots, qu'il faut savoir comprendre et interpréter dans leur ensemble.
Structure grammaticale d'un texte
Un texte est une suite de mots, agencés dans un certain ordre. Prenons l'analogie avec les images. Une image est une suite de pixels, agencés aussi dans un ordre bien précis. Cet ordre est justement ce qui donne du sens à l'image.

Si les pixels étaient dans un ordre différent, l'image n'aurait plus le même sens.

De la même manière, l'ordre des mots dans un texte et leur agencement grammatical est ce qui donne sens au texte. La phrase La société ABC est condamnée à payer 1000 euros à Madame ZYX n'a pas la même signification que la phrase MadameZYX est condamnée à payer 1000 euros à la société ABC , bien que les mêmes mots soient utilisés. L’algorithme doit donc non seulement comprendre les mots mais aussi comprendre la structure grammaticale.
Représentations d'un texte
Nous avons vu comment représenter un mot par un vecteur de nombres. De la même manière, il peut être utile de représenter une phrase, un paragraphe ou même un texte entier par un vecteur, les rendant ainsi comparables, ce qui nous permettrait par exemple d'offrir de la recommandation de contenus similaires (décisions similaires, faits ou arguments juridiques similaires, ...).
Une première approche naïve, qui peut être pertinente, est de prendre la moyenne des vecteurs des mots qui composent le texte. Si nous reprenons l'analogie avec les images, et que nous faisons la moyenne des pixels qui composent l'image, nous obtenons :

Il est assez évident que nous perdons beaucoup d'informations sur l'image originale avec cette méthode. Néanmoins, cette technique peut s'avérer suffisante pour certaines tâches. Par exemple, si l'objectif était de prédire si la scène se passe à la plage, en ville ou à la montagne, l'algorithme pourrait, grâce à la couleur jaune dominante, prédire de manière confiante qu'il s'agit de la plage. De la même manière, pour prédire le domaine du droit d'une décision, une simple moyenne des mots relatifs à du droit commercial peut laisser émerger une forte composante commerciale et ainsi suffire à l'algorithme.
En revanche, si l'objectif était de trouver où est Charlie, l'algorithme n'a, en l'état, pas assez d'informations.
Des techniques plus poussées, que nous ne détaillerons pas ici, permettent d'obtenir des représentations vectorielles de textes plus pertinentes, et de comparer ainsi deux documents juridiques.
Représentations contextualisées
Les dernières avancées en traitement du langage naturel se sont tournées vers des représentations contextualisées de mots : un mot n'a de sens que dans un contexte donné, de la même manière qu'un pixel d'image n'a de portée que dans une image donnée.
Cela permet notamment de gérer la polysémie d'un mot. Le mot avocat, par exemple, peut avoir plusieurs significations. Grâce à ces nouvelles représentations, le vecteur associé à ce mot dans le texte L'avocat de la défense se retrouverait éloigné du vecteur de ce même mot dans le texte Une salade à l'avocat.
Les enjeux restants pour Doctrine
Plusieurs défis restent encore ouverts, et ne sont pas toujours complètement résolus dans le domaine du traitement du langage naturel.
Evolution de la langue dans le temps
Une langue est susceptible d'évoluer dans le temps : de nouveaux termes peuvent voir le jour (par exemple récemment, le terme Covid-19) et comme évoqué précédemment, les modes de rédaction peuvent évoluer (l'ordre administratif ainsi que la Cour de cassation ont récemment changé leur format de rédaction). Il convient donc de mettre en place des mécanismes permettant d'avoir des algorithmes à jour pour comprendre les évolutions récentes du langage et des modes de rédaction.
Longueur des documents juridiques
Les algorithmes évoqués précédemment requièrent des puissances de calcul conséquentes. En particulier, plus le document traité est long, plus l'algorithme est gourmand en ressources. C'est pourquoi il est encore difficile aujourd'hui de traiter de très longs documents pour certaines tâches. Or les décisions de justice peuvent parfois être très longues (exemple). Des avancées récentes en traitement en langage naturel proposent des solutions très prometteuses pour pallier ces limitations.
Volumétrie de données annotées
L'un des principaux enjeux à Doctrine, et de manière générale en Intelligence Artificielle, reste l'accès à des données annotées pour des tâches très précises. Cette phase d'annotation peut être très longue, coûteuse et chronophage. Par ailleurs, elle demande une expertise juridique particulière et peut donc difficilement être externalisée. Là aussi, des résultats récents dans le domaine laissent entrevoir la possibilité d'algorithmes présentant une capacité de généralisation supérieure, ce qui diminuerait d'autant la dépendance au volume de données annotées requis.
Ce sont autant d'enjeux que nous adressons à Doctrine, en bénéficiant notamment des dernières avancées en traitement du langage naturel que nous suivons au quotidien. Nous avons en effet investi dès les premiers mois sur la veille scientifique, ce qui nous a permis de comprendre en profondeur nos contenus, de les lier entre eux et d'en extraire leur sens.
Conclusion
Depuis 4 ans, nous avons fait le pari de la transformation numérique de la justice et y investissons massivement pour pouvoir répondre aux problématiques évolutives des avocats et juristes. Le droit est une matière vivante qui évolue constamment. La technologie doit s’y adapter constamment pour en comprendre les subtilités et permettre aux professionnels du droit de bâtir des stratégies juridiques gagnantes.
L’anonymisation des décisions de justice à grande échelle (https://blog.doctrine.fr/lanonymisation-des-decisions-de-justice/) et le traitement automatique du langage juridique sont au coeur de la technologie Doctrine. Dans les prochains articles, nous verrons comment la technologie Doctrine s’appuient sur ces piliers pour faire fonctionner le moteur de recherche et la veille juridique personnalisée.
Si vous êtes intéressés par le Natural Language Processing, inscrivez-vous à notre meetup NLP https://www.meetup.com/fr-FR/Paris-NLP/. Nous y organisons régulièrement des échanges avec des experts mondiaux de l’intelligence artificielles sur de nombreuses applications. Déjà plus 5 000 personnes en sont membres !
Sources
[1] L'algorithme le plus connu pour faire cela a été présenté en 2013 par une équipe de chercheurs de Google (Mikolov et al.) et se nomme Word2vec (https://arxiv.org/pdf/1301.3781.pdf).
